This paper is written by Ross Girshick(Microsoft Research)
논문 본문 정리내용 기록 남기기(개인 공부 포스팅입니다)
지난 글인 Fast R-CNN 정리(2)의 마지막 내용인 Fine-tuning detection
이어서 진행하겠습니다.
[2.3 Fine-tuning for detection] - 지난 포스팅 이어서..
SPP net is unable to update weights... Then why??
Root Cause : Back-Propagation in SPP net is not efficient!!!!
Not Efficient = Inefficient! ( Because of Training Inputs are large)
-> 가끔식 ROI가 수용 구역을 전체 이미지로 설정할 수 있기 때문이다.
But, Fast R-CNN training is different!
Fast R-CNN training Strategy)
Sample N images hierarachically & Sample R/N ROIs from each image.
So, from singular image-> multiple ROIs will be extracted(shares computation & memory)
Therefore, small value in number of images(N) is needed!
(Smaller N will decrease mini-batch computation!)
For example, with 2 images(N=2) and 128 ROIs(R=128)
training will be 64x faster than sampling only 1 ROI(R=1) from 128 different images(N=128)

Fast R-CNN uses streamlined training process with one fine-tuning stage that jointly optimizes
a softmax classifier and bounding box regression.
There are several components of this procedure.
(Loss, mini-batch, sampling strategy, back-propagation through ROI pooling, SGD hyper-parameters)
[Mulit task Loss]
Fast R-CNN has 2 splited output layers.

First one Output)
K+1 Classification based on discrete probability by using softmax per ROI.
Second one Output)
bbox regression offsets for each of K object classes. (DataType : tuple)

Second layer output tk adjustment of objet proposal.
(scale-invariant & log-space h/w shift)
Formula Definition)
1. u : ground truth class & Each ROI is labeled with this "u"
2. v: ground truth bbox regression target(ideal position of bbox)
This paper use "multi-task loss" L on each labeled ROI to jointly train for
Classification & bbox Regression.
Equation Summary)
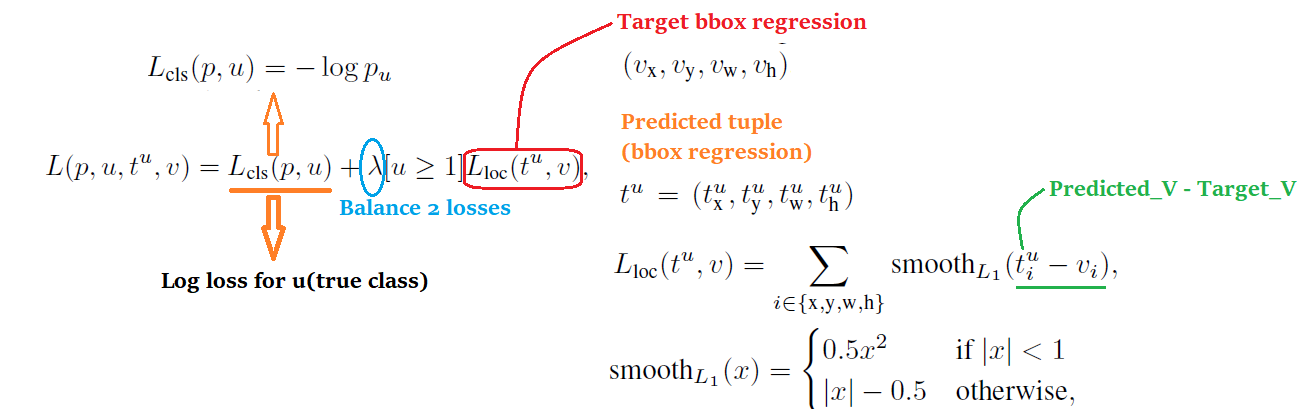
Bracket [u>=1]
Catch-all background -> u=0 -> That means L loc is ignored.(No ground truth for Background ROIs)
[Mini-batch Sampling]
N=2 (number of images)
R=128(number of ROI)
With those two conditions, this paper
considers only 25% of the ROIs with IOU figure at least 0.5
& Foreground object classes(u>=1 except u=0(background))
The remaining ROIs will be sampled from object proposals as background(label u=0)
(IOU range : [0.1,0.5))
[Back-propagation through ROI pooling layers]
xi=i-th activation input -> ROI pooling layer
yrj=j-th output of r-th ROI
single value of xi => assigned to several different output values yrj(N개)

ROI pooling layer backward function)
->compute partial derivative(편미분) a L/a xi
Also a L/ a yrj will be accumlated if i is the argmax selected for yrj by max pooling.
(condition of Bracket)
[SGD hyper-parameters]
Fully Connected Layers(FC) -> used for Softmax Classification & BBox Regression
-> Initialized from zero-man Gaussian distributions(정규분포)
Standard Deviations(표준 편차) : 0.01 & 0.001
[2.4 Scale Invariance]
To achieve Scale Invariance?
There are 2 ways~
1. Brute force learning<-use image pyramids
Both training & testing -> each image should be resized(redefined) to pre-defined pixel size
2. Multi-scale Approach
Image pyramid ==> execute scale-normalize operation for each object proposal
Multi-scale training ==> Test with smaller networks only!(Due to GPU memory limits)
이후 논문 공부도 포스팅 예정입니다.
오늘도 감사합니다.
'논문 공부' 카테고리의 다른 글
| AUTOVC 논문 정리(1) (0) | 2021.02.27 |
|---|---|
| R-CNN & Fast R-CNN 비교 정리 (0) | 2021.02.07 |
| R-CNN 정리(3) (0) | 2021.01.21 |
| R-CNN 정리(2) (0) | 2021.01.14 |
| R-CNN 정리(1) (0) | 2021.01.11 |
| Fast R-CNN 정리(4) (0) | 2021.01.07 |
| Fast R-CNN 정리(2) (0) | 2021.01.03 |
| Fast R-CNN 정리(1) (0) | 2021.01.02 |




댓글